Welcome to the web page of team hiraki. It is draft page so it will change soon.
Our purpose is to develop fast and scalable microprocessor on FPGA. Our project team "team Hiraki" have succeeded to develop pipelined scalar processor on FPGA platform and it can run Ray-Tracing Program. Now we are developing superscalar processor and it's software environment. This page show you our microprocessor's architecture and software technology.
Our project started in 2003. And we show first practical processor "Ultra Hierarchy II" and it's software environment at 2003 Processor Speed Contest in University of Tokyo Department of Information Science. And our team get first prize in this contest. Our processor can achieve best performance in this contest.
We are making next processor which has superscalar architecture. It will can run on field programmable gate arrays. If we can, we want to exploit this reconfigurable aspect. FPGA's wire latency is critical but superscalar architecture is complex. So to achieve high facility and high performance on FPGA is very hard. But if we can develop fast superscalar architecture on FPGA, we think it can be very useful.
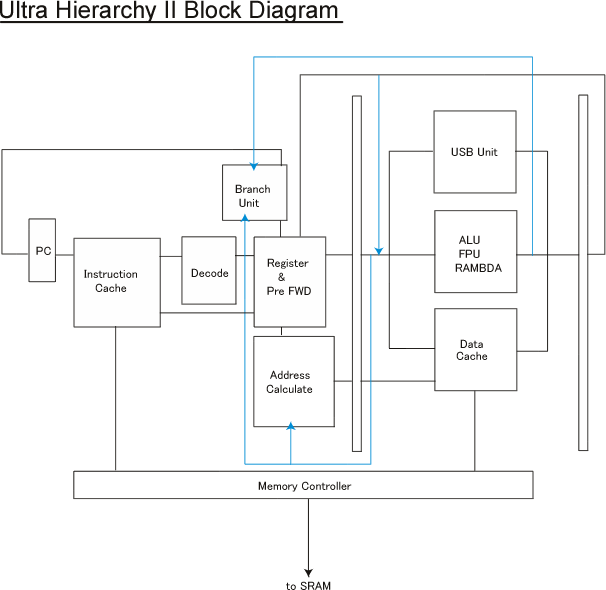
Now we are going to explain our processor's architecture briefly. Our processor has three pipeline stage. First stage components are program counter,instruction cache,decoder,branch unit,register file(read),pre-forwarding unit and address calculation unit. Second stage components are data cache,ALU,floating point unit,USB unit,and other execution unit. Third stage component is a register write.
This processor can run on 50MHz frequency(Xilinx xc2v1000(speed grade -5)device). Most of scalar pipelined processor can't achieve 0.7IPC. But ultra hierarchy II processor can achieve 0.74IPC on 50MHz. To achieve this performance, we added it data cache,pre-forwarding unit,floating point unit,and so on. And we took ultra forwarding technology. for example it forwarding component can forward previous load data to next instruction. And if processor find slt+beq pair, processor resolve it's hazard. This processor can a lot of forward data of second stage to first stage. And optimizing compiler can generate extremely optimized code for this processor. And assembly program can optimize this code to eliminate hazards which cannot be eliminated by the processor. We show here a diagram of this processor. Blue lines are forwarding lines.
This processor have high performance floating point unit. This unit can execute most of complex floating point instructions in 2 clocks. And it can execute more complex instructions(sqrt,div) in 5 clocks. It helps to execute floating point arithmetical programs fast.
This processor have cache system which runs with other units concurrently. If cache miss occurs, Speculatively executed actions will be flushed. For example, instruction cache and decorder can run parallely.
Data cache has prefetch feature. If one cache miss occurs then cache system fetch three subsequent word data. And this action can run with subsequent instructions if next instructions don't meet data cache misses. So cache system of Ultra Hierarchy II can execute effectively programs.
RAMBDA is a high-performance small storage unit. We can always access RAMBDA area for one clock. We can use this small storage for constant,frequently used data,etc...
Branch unit of this processor can determin branch target and whether branch is taken or not taken in first stage. So this processor can execute any program without delayed slot. Advantage of this no delayed slot is to reduce instruction cache misses. If source register values have not yet been written, this processor can forward its data if it can be forwarded.
Pre-forwarding unit calculate whether forwarding is needed or not needed in the next cycle. And this unit pass this information to the next stage. So we can success to lighten the weight of the second stage. Pre-forwarding unit also forward data in the third stage. Register file of this processor write values in rise-edge. So Pre-forwarding unit enables using third-stage values in the second stage.
We adopt ISO(Immediate value Special Optimization) Architecture. So we can forward immediate value in the second stage to the first stage immediately. So address calculation of ISO load/store instructions can run with no hazards. The forwarding line from second stage to branch unit and address calculation unit indicates this forwarding. And we also adopt ELHAZARD(ELiminate HAZARds Dynamically) Architecuture. This architecture enables to forward a result of slt,slti,smti(it often used to compare to next branch instruction) instruction to the next branch instruction dynamically. So we can eliminate most of branch hazards. The blue line of this block diagram from ALU's output to branch unit indicates this forwarding technique. But in later, we knew this architectural technique was very well-known technique.
Our processor now has several features. But initially this processor had few features. So we experienced efficiency of individual techniques. For example when we put data cache system, this processor can run ray-tracing program half time. So we can knew data cache is very efficient. We think this spiral development model is very useful in educational object processor development. And processor development from scratch is very hard but we can gain knowledges of trade-offs and thoughts of many problems to construct whole processor.